
我院在机器人策略学习研究方面取得进展
近日,我院李鹏副研究员协同AGIROS开源社区团队在机器人策略学习研究方面取得进展。针对当前主流策略学习模型生成轨迹不够平滑高效的问题,团队提出了一种基于Kolmogorov-Arnold Networks(KANs)的扩散策略模型KAN Policy (KP),并在多个模拟及真实机器人任务中进行了实验。相关成果论文《KAN Policy: Learning Efficient and Smooth Robotic Trajectories via Kolmogorov-Arnold Networks》已被机器人技术领域顶级期刊IEEE Robotics and Automation Letters(RA-L)接收。第一作者为硕士研究生陈子康,第三作者为硕士研究生余子丫。
目前,基于扩散模型的策略(Diffusion-based Policy)在机器人模仿学习领域取得了巨大成功。但大部分此类模型依赖于CNN或Transformer架构,其内在的离散计算特性,限制了它们生成平滑连续运动轨迹的能力。因此,当机器人执行任务时,我们常常观察到轨迹中的顿挫和急动,这不仅延长了任务时间,也为物理安全带来了隐患。那么,我们能否从神经网络架构的层面上进行革新,让模型像熟练的物理系统一样,自然地生成平滑、高效的运动轨迹,从“数字的步进”进化为“物理的流畅”呢?
针对这一问题,团队首次将新型的KANs引入机器人策略学习,开发出能够在生成过程中保持内在连续性的新模型——KAN Policy (KP),使其具备了学习并生成高效、平滑轨迹的能力。
KAN Policy (KP) 以主流的扩散策略为基础框架,但其核心革新在于用KAN替换了传统网络中的关键组件。与传统网络使用固定的激活函数不同,KAN的网络连接本身就是可学习的、由样条曲线构成的函数。这种设计使得整个网络本质上是连续的。团队针对不同架构专门设计了:
1、Emb-KAN模块:用于CNN模型,它使用自适应样条嵌入来调整不同特征之间的相互作用,确保特征保持连接,在高维特征空间中保持了结构的连续性。增强了网络在高维数据中捕捉复杂模式的能力。
2、Group-KAN模块:用于Transformer模型,使用有理函数作为基函数且分组共享参数,学习特征间的连续关系,输出平滑的动作序列。
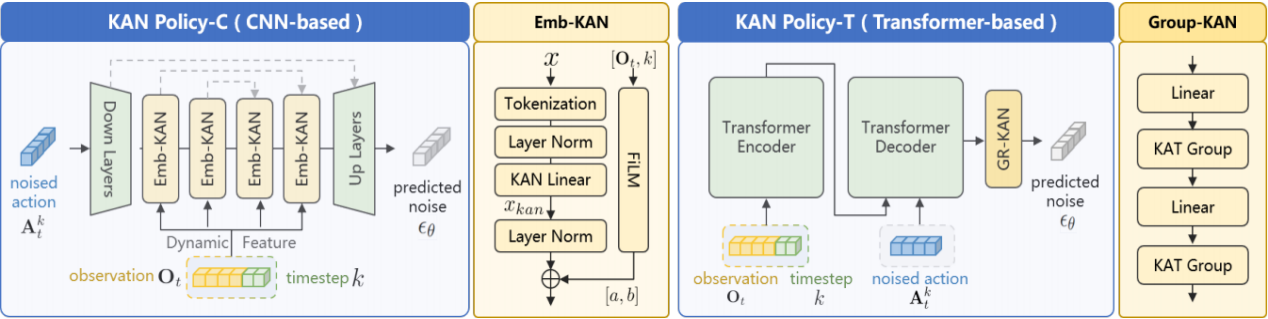
图1 Emb-KAN和Group-KAN
通过在交互中学习大量专家示例,KAN Policy能够不断优化其对平滑轨迹的建模。基于其内在的连续性,模型生成的轨迹在时间和空间上都表现出极佳的流畅度。
团队在七个模拟任务和三个真实世界机器人任务中进行了广泛实验。结果表明,受益于其连续的结构设计,KAN Policy的综合性能显著提升,在模拟和真实世界实验中,平均成功率、执行效率和轨迹平滑度均大幅超越基线模型。尤其是在真实机器人上,成功率平均提升了53.8%,平滑度提升了29.4%。
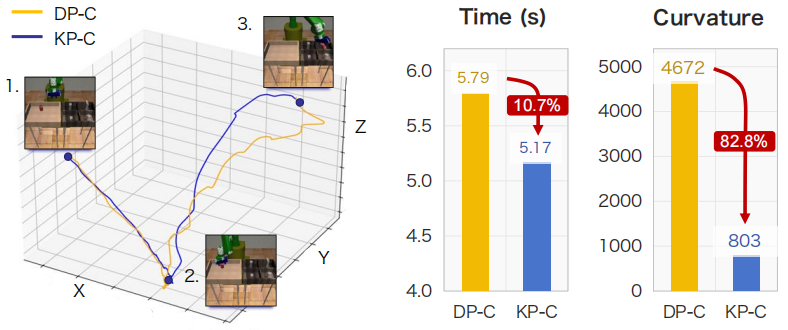
图2 模拟环境中“搬运”任务的性能对比
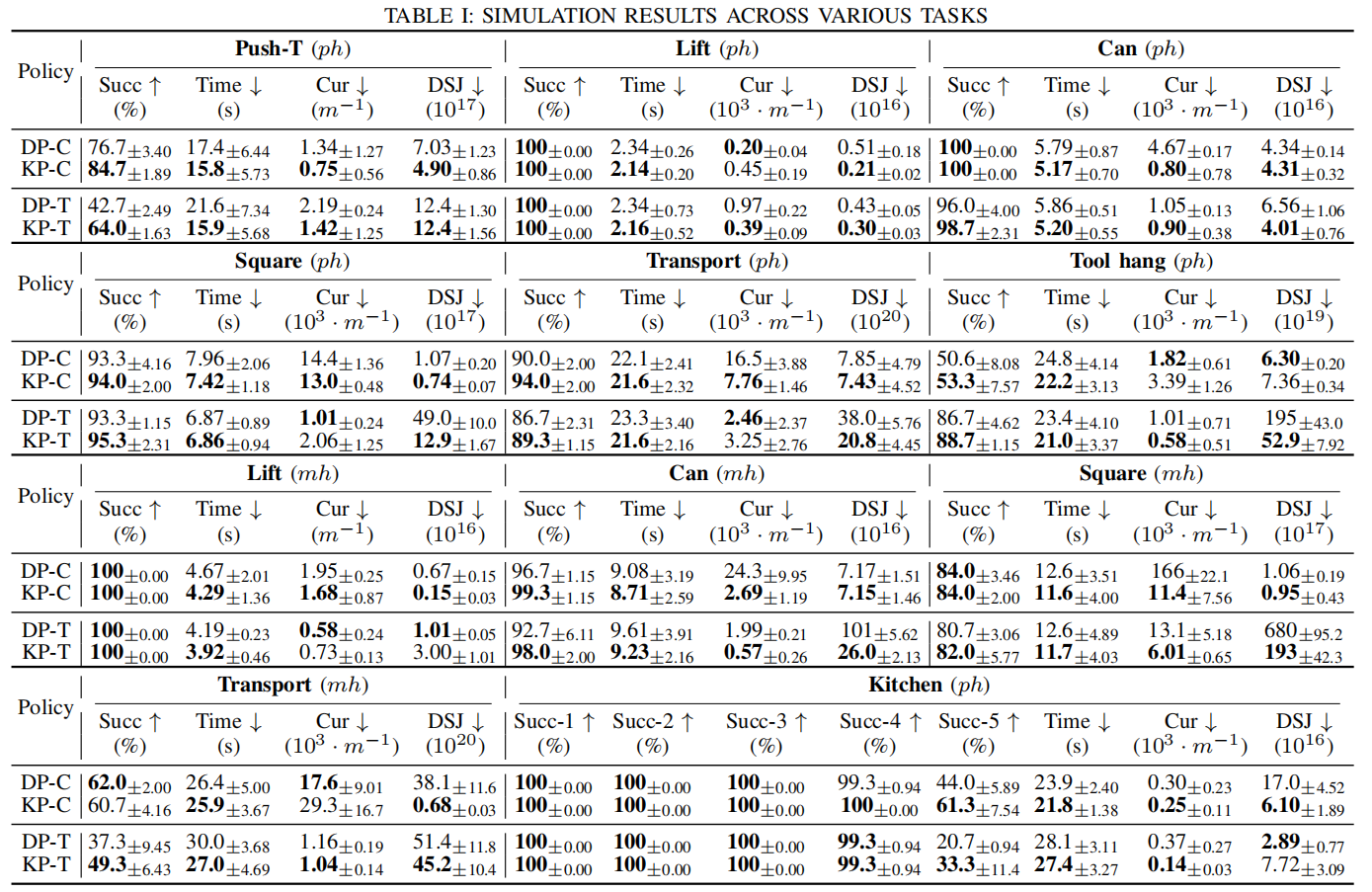
图3 模拟实验任务及其结果

图4 实机实验结果
在现实世界中,从工业装配到家庭服务,机器人任务都对运动的平滑、高效和安全有着极高要求。KAN Policy通过对神经网络基础范式的探索,为解决众多现实世界机器人控制问题提供了新的方向和思路。
本项工作获得南京市重大科技专项(综合类)多模态智能协作机器人关键技术与系统项目资助。